| Model |
Table Understanding (TU) |
Table Basic Operation (TBO) |
Table Computational Operation (TCO) |
Data Analysis (DA) |
Advanced Data Analysis (ADA) |
Overall Score | |
|---|---|---|---|---|---|---|---|
| May 18, 2026 | Kimi-K2.5 Moonshot AI |
85.862 | 94.69 | 85.63 | 94.39 | 63.78 | 84.18 |
| May 18, 2026 | gemini-3-pro |
82.968 | 93.69 | 80.165 | 95.235 | 64.44333333 | 82.91 |
| May 18, 2026 | JT-DA JIUTIAN Research |
84.574 | 91.805 | 83.5075 | 94.065 | 61.11333333 | 82.31 |
| May 18, 2026 | Qwen3.6-27B Alibaba |
86.12 | 88.845 | 83.84 | 94.845 | 62.92666667 | 81.31 |
| May 18, 2026 | Qwen3.5-397B-A17B Alibaba |
84.142 | 88.8725 | 82.66 | 89.5125 | 63.17333333 | 81.03 |
| May 18, 2026 | MiniMax27 MiniMax |
85.636 | 92.565 | 80.515 | 94.05 | 53.195 | 80.5 |
| May 18, 2026 | Qwen3-235B-A22B-Thinking Alibaba |
83.114 | 89.47 | 83.225 | 89.275 | 60.54833333 | 80.4 |
| May 18, 2026 | Qwen3.6-35B-A3B Alibaba |
86.081 | 90.49 | 83.165 | 88.59 | 60.51833333 | 80.34 |
| May 18, 2026 | Qwen3.5-35B-A3B Alibaba |
85.076 | 91.895 | 82.97 | 92.735 | 58.555 | 80.13 |
| May 18, 2026 | Qwen3.5-27B Alibaba |
85.698 | 93.04 | 82.82 | 86.205 | 59.415 | 79.92 |
| May 18, 2026 | Qwen3.5-122B-A10B Alibaba |
85.07 | 92.3 | 83.2 | 91.46 | 61.025 | 79.15 |
| Feb 3, 2026 | doubao-1.5-pro ByteDance |
79.996 | 87.12 | 79.9 | 90.5 | 54.818 | 78.47 |
| Sep 1, 2025 | QwQ-32B Alibaba |
83.22 | 81.98 | 83.275 | 83.275 | 58.595 | 78.15 |
| Sep 1, 2025 | Qwen3-32B Alibaba |
81.084 | 83.06 | 82.78 | 84.415 | 57.003 | 77.67 |
| Feb 3, 2026 | gpt-4o OpenAI |
81.09 | 80.21 | 81.145 | 89.288 | 56.22 | 77.59 |
| Sep 1, 2025 | Qwen2.5-72B-Instruct Alibaba |
80.462 | 80.17 | 80.225 | 85.093 | 53.555 | 75.9 |
| Sep 1, 2025 | Qwen3-14B Alibaba |
81.506 | 84.6 | 82.17 | 76.405 | 52.225 | 75.38 |
| Feb 3, 2026 | gpt-4o-mini OpenAI |
75.496 | 76.88 | 78.91 | 84.85 | 49.062 | 73.04 |
| Sep 1, 2025 | Deepseek-R1-Distill-Qwen-32B Deepseek |
76.914 | 77.85 | 77.41 | 81.545 | 49.948 | 72.73 |
| Sep 1, 2025 | Llama-3.1-70B-Instruct Meta |
68.012 | 78.9 | 77.595 | 81.06 | 56.223 | 72.36 |
| Sep 1, 2025 | Qwen3-8B Alibaba |
79.052 | 80.03 | 78.465 | 71.32 | 49.098 | 71.59 |
| Sep 1, 2025 | TableGPT2-7B Zhejiang University |
71.632 | 71.00 | 74.685 | 85.12 | 48.212 | 70.13 |
| Sep 1, 2025 | Deepseek-R1-Distill-Qwen-14B Deepseek |
75.028 | 74.12 | 72.76 | 73.73 | 39.18 | 66.96 |
| Sep 1, 2025 | Table-R1-Zero-7B Yale |
73.53 | 60.655 | 73.655 | 80.07 | 45.853 | 66.75 |
| Dec 2, 2025 | DeepSeek-R1-0528-Qwen3-8B DeepSeek |
77.292 | 78.21 | 69.035 | 64.273 | 40.387 | 65.84 |
| Sep 1, 2025 | Qwen2.5-Coder-7B-Instruct Alibaba |
67.612 | 73.99 | 68.02 | 80.025 | 38.832 | 65.7 |
| Sep 1, 2025 | Qwen2.5-7B-Instruct Alibaba |
69.052 | 68.23 | 67.3 | 79.755 | 41.915 | 65.25 |
| Sep 1, 2025 | Seed-Coder-8B-Instruct ByteDance |
64.698 | 71.16 | 66.17 | 82.085 | 41.582 | 65.14 |
| Sep 1, 2025 | Qwen2.5-Math-72B-Instruct Alibaba |
74.416 | 66.24 | 69.24 | 75.573 | 38.897 | 64.87 |
| Sep 1, 2025 | Llama-3.1-8B-Instruct Meta |
59.4 | 70.13 | 63.81 | 76.445 | 35.35 | 61.03 |
| Sep 1, 2025 | Deepseek-R1-Distill-Qwen-7B Deepseek |
60.72 | 58.58 | 53.855 | 71.463 | 29.313 | 54.79 |
| Sep 1, 2025 | Deepseek-R1-Distill-Llama-8B Deepseek |
62.689 | 56.52 | 47.8 | 50.773 | 19.97 | 47.55 |
| Sep 1, 2025 | Yi-Coder-9B-Chat 01-AI |
43.97 | 57.05 | 47.01 | 56.095 | 33.172 | 47.46 |
| Sep 1, 2025 | Table-R1-SFT-7B Yale |
60.404 | 23.46 | 24.1 | 43.01 | 37.603 | 37.72 |
About TReB
TReB is a comprehensive table reasoning evolution benchmark, which measures both shallow table understanding abilities and deep table reasoning abilities.
Overall, we construct a high quality dataset to evaluate 5 core skills of LLMs: Table Understanding (TU), Table Basic Operation (TBO), Table Computational Operation (TCO), Data Analysis (DA), and Advanced Data Analysis (ADA).
Accordingly, we propose a total of 20 sub-tasks.
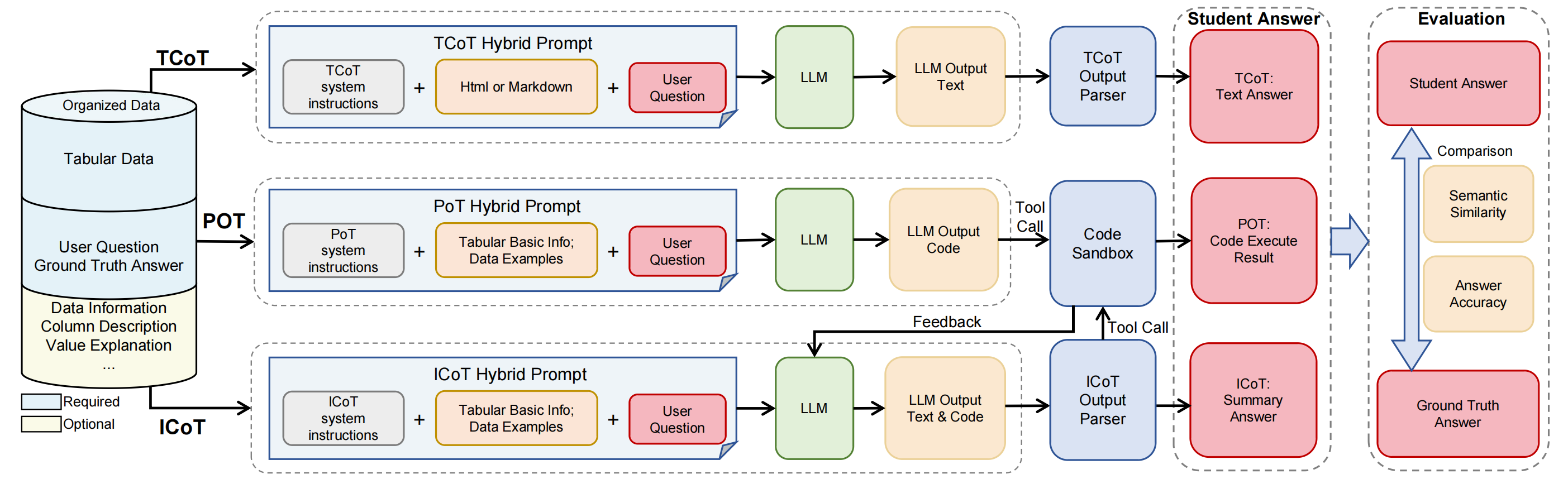
The evaluation framework supports 3 distinct inference modes, TCoT, PoT and ICoT, encouraging more robust reasoning.
News
-
Feb. 3, 2026:
We have updated the evaluation results of some models on the leaderboard and removed the display of the Rouge-L metric, retaining only the LLM-as-a-judge metric (which is relatively fairer).
Jun. 18, 2025:🔥🔥 The benchmark paper, code and dataset are all released! Please check and submit your result to leaderboard!!
Thank you for all the feedback!!!
Challenges from TReB
Submission
🤗🤗 We warmly welcome submissions to our leaderboard, including both your own methods and contributions
showcasing the latest model performance! TReB features two separate leaderboards. Please refer to
the Submission Guidelines below for details, and submit your results as instructed to
jttreb2025@gmail.com.
Citation
@misc{li2025trebcomprehensivebenchmarkevaluating,
title={TReB: A Comprehensive Benchmark for Evaluating Table Reasoning Capabilities of Large Language Models},
author={Ce Li and Xiaofan Liu and Zhiyan Song and Ce Chi and Chen Zhao and Jingjing Yang and Zhendong Wang and Kexin Yang and Boshen Shi and Xing Wang and Chao Deng and Junlan Feng},
year={2025},
eprint={2506.18421},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.18421},
}